



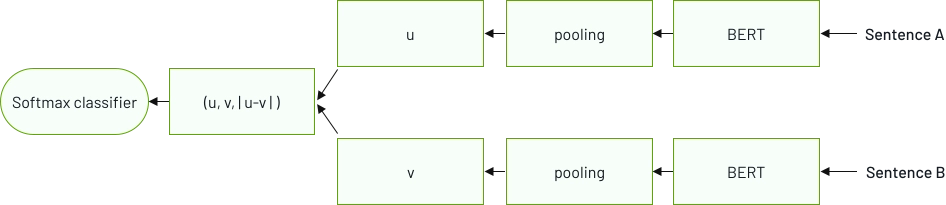

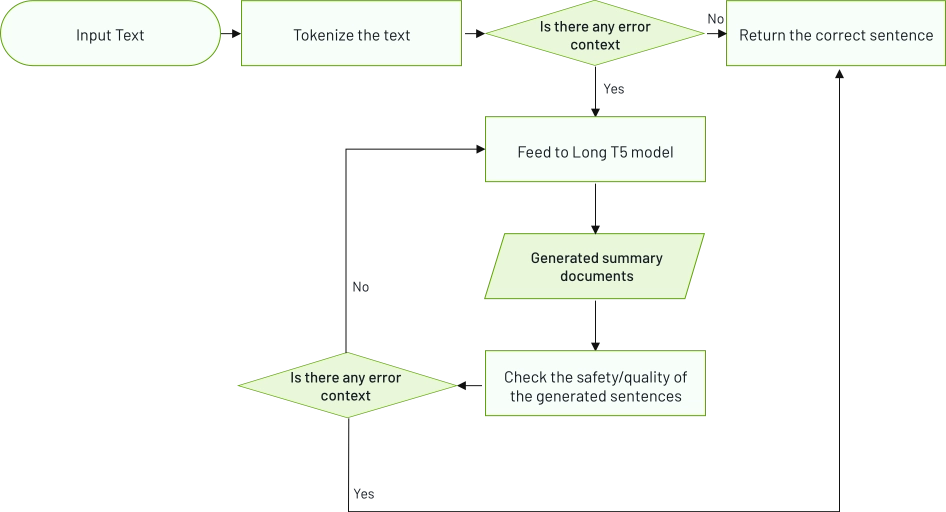


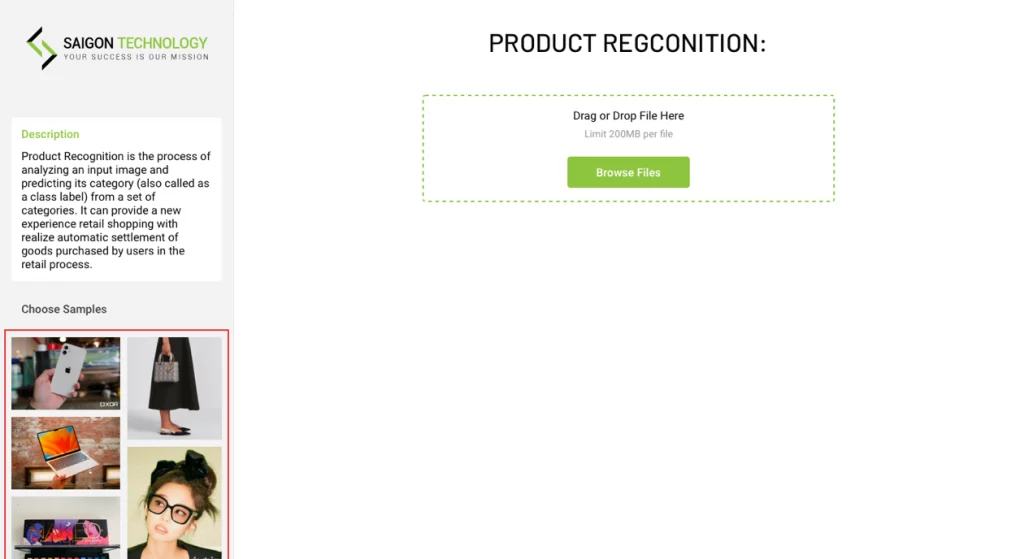

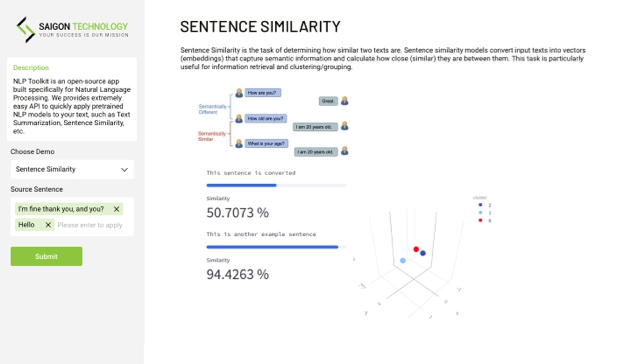


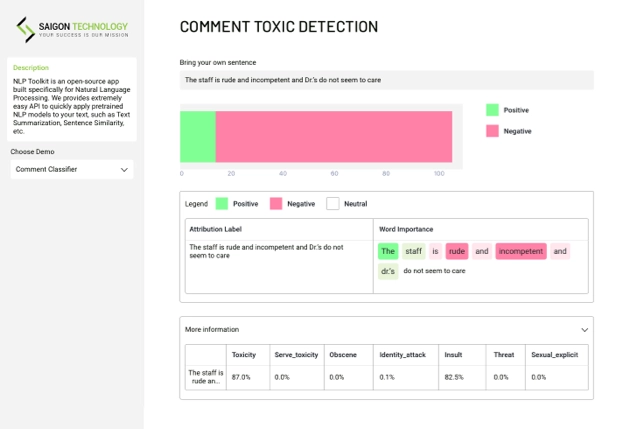
Utilizing AI-based Computer Vision techniques, the Product Recognition system autonomously detects and categorizes products present within images or videos.
Let’s Talk
Together with our developers and analysts, we begin by discussing and analysing our client’s needs, sketching the outline.