Lass Uns Reden
Beginnen Sie die Konversation mit unseren Analysten und Entwicklern. Zusammen erheben wir die Bedürfnisse und skizzieren die neue Lösung


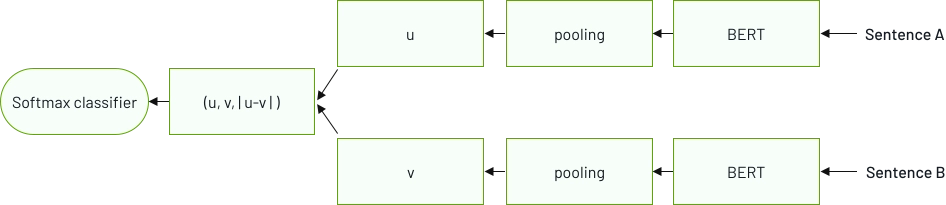
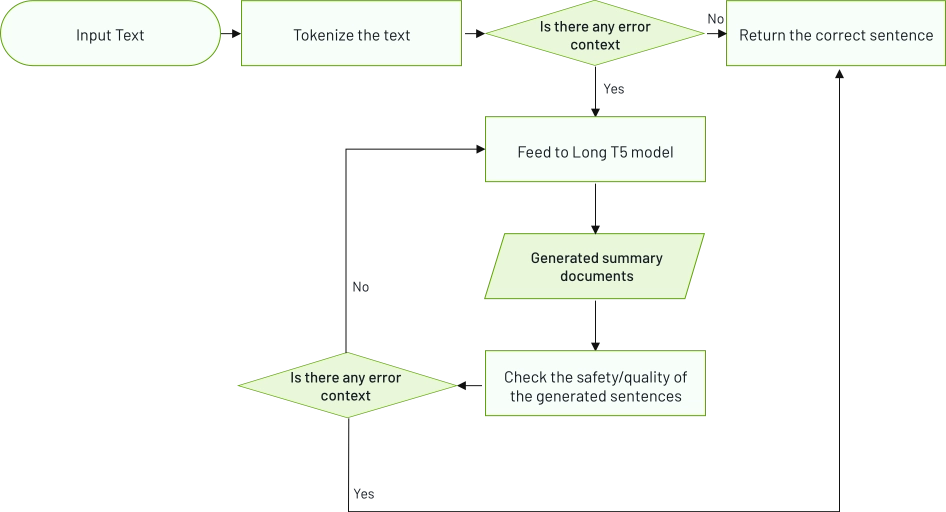
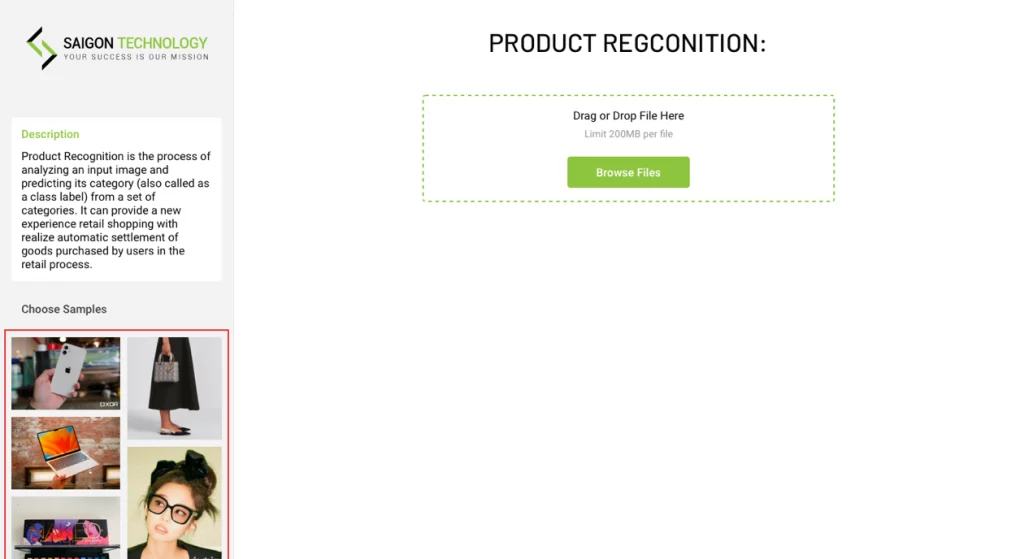
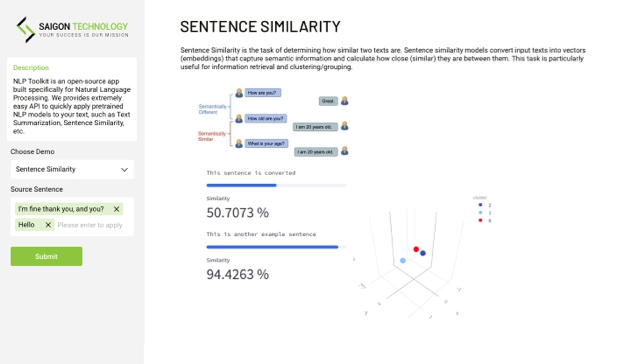
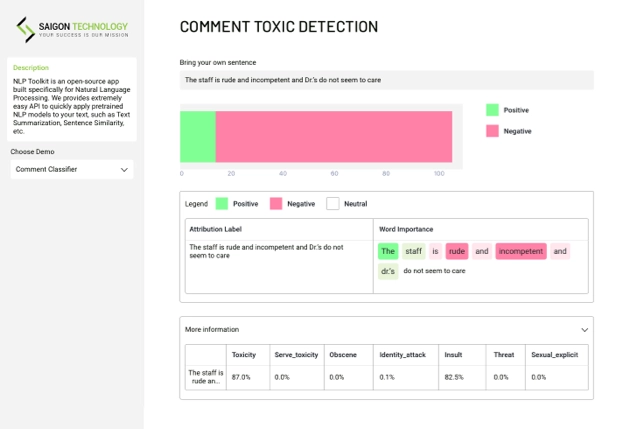
Natural Language Processing (NLP) ist ein Bereich der Informatik und der künstlichen Intelligenz, der sich auf die Interaktion zwischen Computern und Menschen in natürlicher Sprache konzentriert. Dabei werden Algorithmen und Modelle entwickelt, die menschliche Sprache analysieren, verstehen und erzeugen können. NLP wird in einer Vielzahl von Anwendungen eingesetzt, darunter Textzusammenfassung, Satzähnlichkeit, Chatbots, Grammatikkorrektur und vieles mehr.