



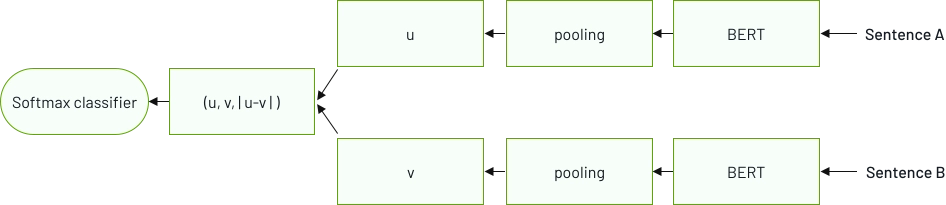

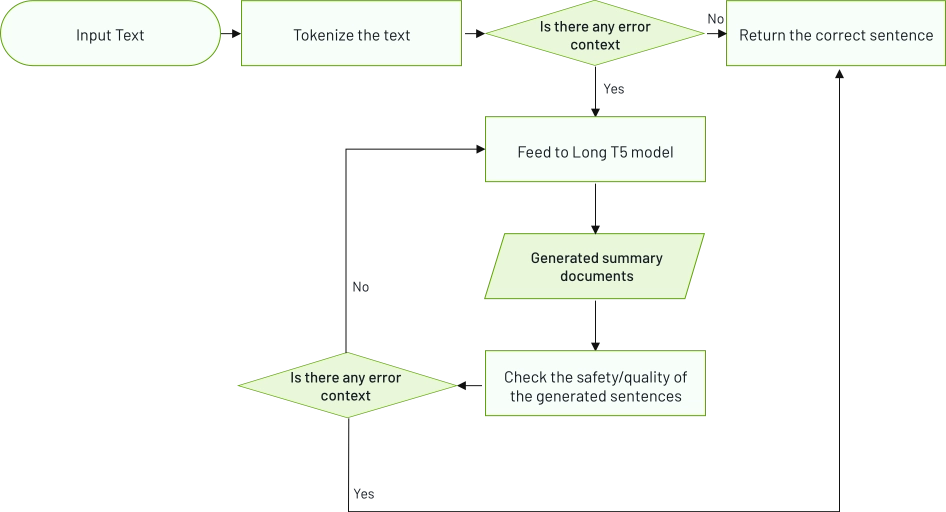


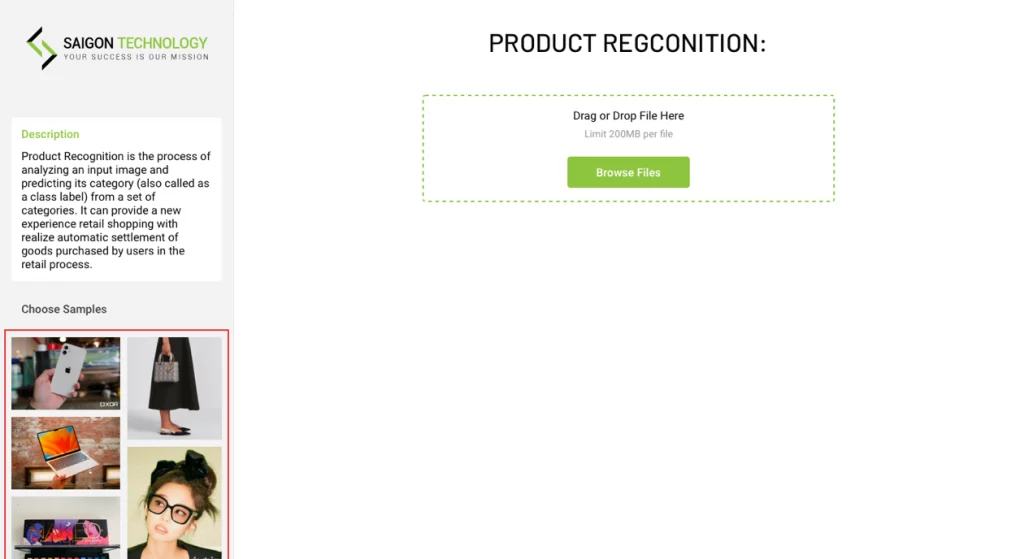

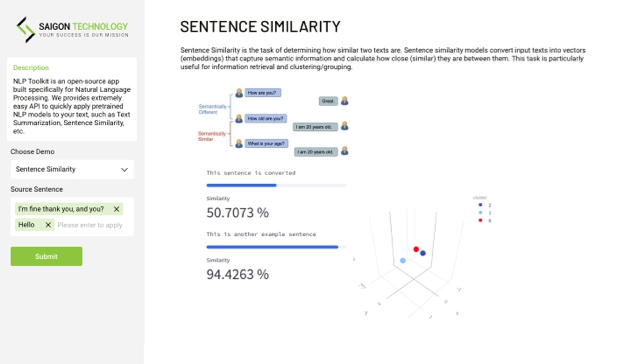


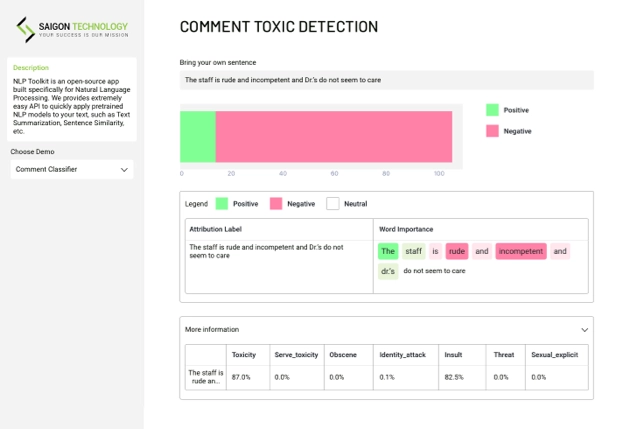
Mithilfe von KI-basierten Computer-Vision-Techniken erkennt und kategorisiert das Produkterkennungssystem selbstständig Produkte in Bildern oder Videos.
Lass Uns Reden
Beginnen Sie die Konversation mit unseren Analysten und Entwicklern. Zusammen erheben wir die Bedürfnisse und skizzieren die neue Lösung